PytorchでMNISTを全結合でやってみる。
Contents
ライブラリインポート
import numpy as np
import matplotlib.pyplot as plt
import torch
import torch.nn as nn
import torch.optim as optim
from torchinfo import summary
from torchviz import make_dot
import torchvision.datasets as datasets
import torchvision.transforms as transforms
from torch.utils.data import Dataset
from torch.utils.data import DataLoaderデータセット構築
MNISTのデータをダウンロードしてDatasetとして保持⇒Dataloaderに渡してミニバッチに分割⇒機械学習。という流れ。
データセット構築において、このDataset ⇒ Dataloaderの流れがPytorchでの一般的なプロセスになるなのだと思う。
MNISTの場合、
train_dataset = datasets.MNIST(root='./data',
train=True,
transform=transforms.ToTensor(),
download=True)
test_dataset = datasets.MNIST(root='./data',
train=False,
transform=transforms.ToTensor(),
download=True)
batch_size = 500
train_loader = DataLoader(train_dataset,
batch_size = batch_size,
shuffle = True)
test_loader = DataLoader(test_dataset,
batch_size = batch_size,
shuffle = False)
for epoch in range(total_epoch):
for train_inputs, train_labels in train_loader:
...
for test_inputs, test_labels in test_loader:
...なんてするのだが、torchvision.datasets.MNISTが一発でDatasetを作ってくれるため、ブラックボックス過ぎて自分で任意のデータを学習したい時にDatasetを作る方法がわからない。
以下、自分でDatasetを作る方法。
torch.utils.data.TensorDataset
numpy配列 ⇒ Tensor ⇒ Datasetで作成する流れ。
from sklearn.datasets import load_iris
iris = load_iris()
from torch.utils.data imoprt TensorDataset
dataset = TensorDataset(torch.FloatTensor(iris.data), torch.LongTensor(iris.target))Irisデータセットについては、2値分類で中身については取り扱ってるので、同じようなデータセットをNumpyで作れば良い。
torch.utils.data.Dataset
TensorDatasetでだいたいいけそうだが、自作のDatasetクラスを作る方法もある。この場合、torchvision.transformsとか使って前処理を色々できるし、__init__()の引数で様々なケースに対応できる。
__len__(): クラスインスタンスにlen()を使った時に呼ばれる関数__getitem__(): クラスインスタンスの要素を参照するときに呼ばれる関数
が必ず必要。
__getitem__()の返り値として、indexで指定された要素のデータとラベルをTensorで返すようにする。
例えば、CSVファイルを読み込んでデータセットにする場合は以下。
import pandas as pd
class WineDataset(Dataset):
def __init__(self, csv_path):
df = pd.read_csv(csv_path)
self.data = df.iloc[:, 1:].values
self.labels = df.iloc[:, 0].values - 1
# len()を使用すると呼ばれる
def __len__(self):
return len(self.labels)
# 要素を参照すると呼ばれる関数
def __getitem__(self, idx):
data = torch.FloatTensor(self.data[idx])
labels = torch.LongTensor(self.labels[idx])
return data, labels
# Wineのデータセット
dataset = WineDataset('https://archive.ics.uci.edu/ml/machine-learning-databases/wine/wine.data')torchvision.datasets.ImageFolder
画像をディレクトリごとに分けておけば、読み込んでデータセットにしてくれる。
サブディレクトリの名前がクラス名となる。クラス ID はクラス名を辞書順ソートして、0, 1, … となる。ImageFolder.class_to_idxでクラス名とクラスIDの対応を取得できる。
img
├── cat
│ ├── a.jpg
│ ├── b.jpg
│ └── c.jpg
├── dog
│ ├── a.jpg
│ ├── b.jpg
│ └── c.jpg
└── mouse
├── a.jpg
├── b.jpg
└── c.jpgdataset = datasets.ImageFolder(root='./img',
transform=transforms.ToTensor())
全結合用MNISTデータセット
今回はCNNでなく全結合層を作って解いてみるので、それ用のデータセットを作る。torchvision.transformsでTensor化⇒正規化[-1,1]⇒1次元化を行う。
transform = transforms.Compose([
transforms.ToTensor(), # Tensor化
transforms.Normalize(0.5, 0.5), # 正規化
transforms.Lambda(lambda x: x.view(-1)) # 1階Tensorに変換
])
train_dataset = datasets.MNIST(root='./data',
train=True,
transform=transform,
download=True)
test_dataset = datasets.MNIST(root='./data',
train=False,
transform=transform,
download=True)データローダーによるミニバッチデータ作成
batch_size = 500
train_loader = DataLoader(train_dataset,
batch_size = batch_size,
shuffle = True)
test_loader = DataLoader(test_dataset,
batch_size = batch_size,
shuffle = False)モデル定義
今回は下記のようなモデルを作る。28×28=784が入力層となり、出力層は0から9までのラベルが10個である。隠れ層は1層で、128個のニューロンを持つ。活性化関数はReLU関数。
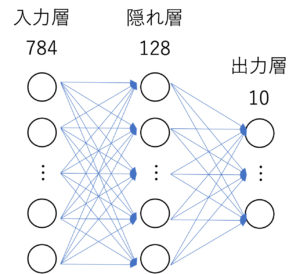
class Net(nn.Module):
def __init__(self, n_input, n_output):
super().__init__()
self.l1 = nn.Linear(n_input, 128)
self.l2 = nn.Linear(128, n_output)
self.relu = nn.ReLU(inplace=True)
def forward(self, x):
x1 = self.l1(x)
x2 = self.relu(x1)
x3 = self.l2(x2)
return x3損失関数と最適化関数定義
net = Net(784, 10) # インスタンスの生成
criterion = nn.CrossEntropyLoss() # 損失関数: 交差エントロピー関数
lr = 0.01 # 学習率
optimizer = optim.SGD(net.parameters(), lr=lr) # 最適化関数: 勾配降下法計算グラフ
とりま計算グラフを出してみる。
dammy_inputs, dammy_labels = next(iter(train_loader)) # データローダーから最初の1つを取得
dammy_output = net(dammy_inputs) # とりま一回計算
loss = criterion(dammy_output, dammy_labels) # とりま一回損失計算
g = make_dot(loss, params=dict(net.named_parameters())) # 計算グラフ可視化
display(g)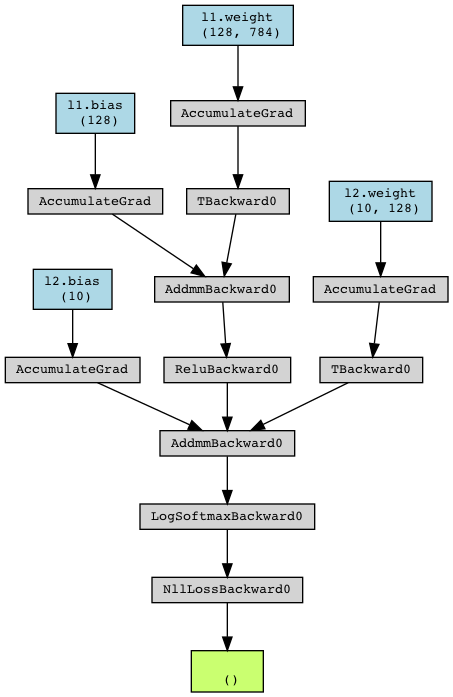
ループ計算
total_epoch = 100 # epoch数
log = np.zeros((0, 5)) # 損失・精度記録用
for epoch in range(total_epoch):
train_acc, train_loss = 0, 0
test_acc, test_loss = 0, 0
n_train, n_test = 0, 0
# 訓練フェーズ
for inputs, labels in train_loader:
n_train += len(labels)
optimizer.zero_grad() # 勾配値初期化
outputs = net(inputs) # 予測計算
loss = criterion(outputs, labels) # 損失計算
loss.backward() # 勾配計算
optimizer.step() # パラメータ更新
predicted = torch.max(outputs, 1)[1] # 予測ラベル選択
train_loss += loss.item() # 損失集計
train_acc += (predicted == labels).sum().item() # 精度集計
# 予測フェーズ
with torch.no_grad():
for inputs_test, labels_test in test_loader:
n_test += len(labels_test)
outputs_test = net(inputs_test) # 予測計算
loss = criterion(outputs_test, labels_test) # 損失計算
predicted_test = torch.max(outputs_test, 1)[1] # 予測ラベル選択
test_loss += loss.item() # 損失集計
test_acc += (predicted_test == labels_test).sum().item() # 精度集計
# 評価値の算出・出力
train_acc = train_acc / n_train
test_acc = test_acc / n_test
train_loss = train_loss * batch_size / n_train
test_loss = test_loss * batch_size / n_test
print(f'Epoch [{epoch + 1}/{total_epoch}], loss: {train_loss:.5f} acc: {train_acc:.5f} val_loss: {test_loss:.5f}, val_acc: {test_acc:.5f}')
ary = np.array([epoch + 1, train_loss, train_acc, test_loss, test_acc])
log = np.vstack((log, ary))結果
損失
plt.plot(log[:,0], log[:,1], 'b', label='train')
plt.plot(log[:,0], log[:,3], 'k', label='test')
plt.xlabel('epoch')
plt.ylabel('loss')
plt.legend()
plt.show()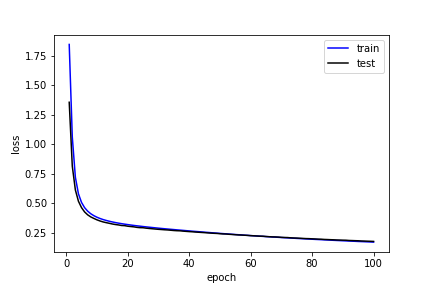
精度
plt.plot(log[:,0], log[:,2], 'b', label='train')
plt.plot(log[:,0], log[:,4], 'k', label='test')
plt.xlabel('epoch')
plt.ylabel('accuracy')
plt.legend()
plt.show()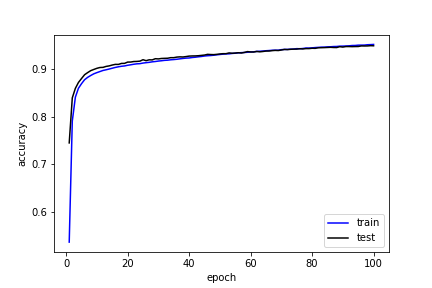
print(f'Init: Loss: {log[0,3]:.5f} Accuracy: {log[0,4]:.5f}')
print(f'Last: Loss: {log[-1,3]:.5f} Accuracy: {log[-1,4]:.5f}')Init: Loss: 1.35532 Accuracy: 0.74520
Last: Loss: 0.17548 Accuracy: 0.94960
精度が95%とかなりよい。たった一層の隠れ層だけで随分と良い精度になるものだ。
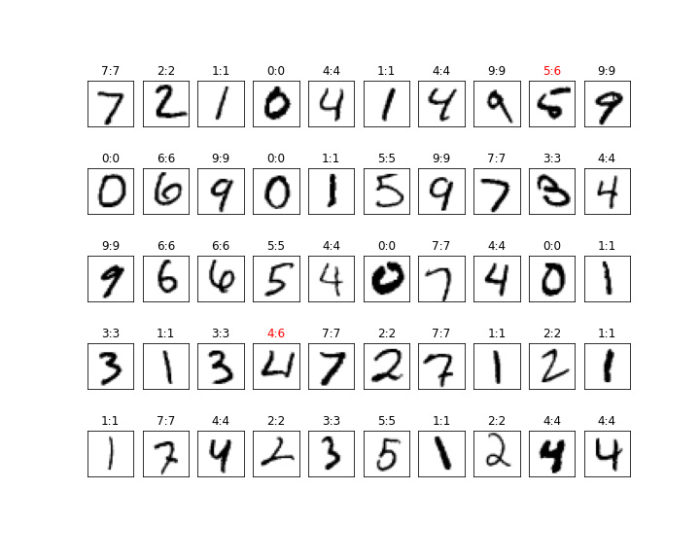
可視化して確認
test_inputs, test_labels = next(iter(test_loader)) # DataLoaderから最初の1セットを取得する
with torch.no_grad():
test_outputs = net(test_inputs)
predicted = torch.max(test_outputs, 1)[1]
plt.figure(figsize=(10, 8))
for i in range(50):
ax = plt.subplot(5, 10, i + 1)
image = test_inputs[i]
label = test_labels[i]
pred = predicted[i]
c = 'k' if pred == label else 'r'
image2 = (image + 1)/ 2 # imgの値の範囲を[0, 1]に戻す
# イメージ表示
plt.imshow(image2.reshape(28, 28),cmap='gray_r')
ax.set_title(f'{label}:{pred}', c=c)
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
plt.savefig('result.png')